Data Pipelines
With 5.4.7, Cloud Connectors are renamed to Data Pipelines
Data Pipelines is a process for data replication from a source (ex:cloud application) to destination (ex:database)
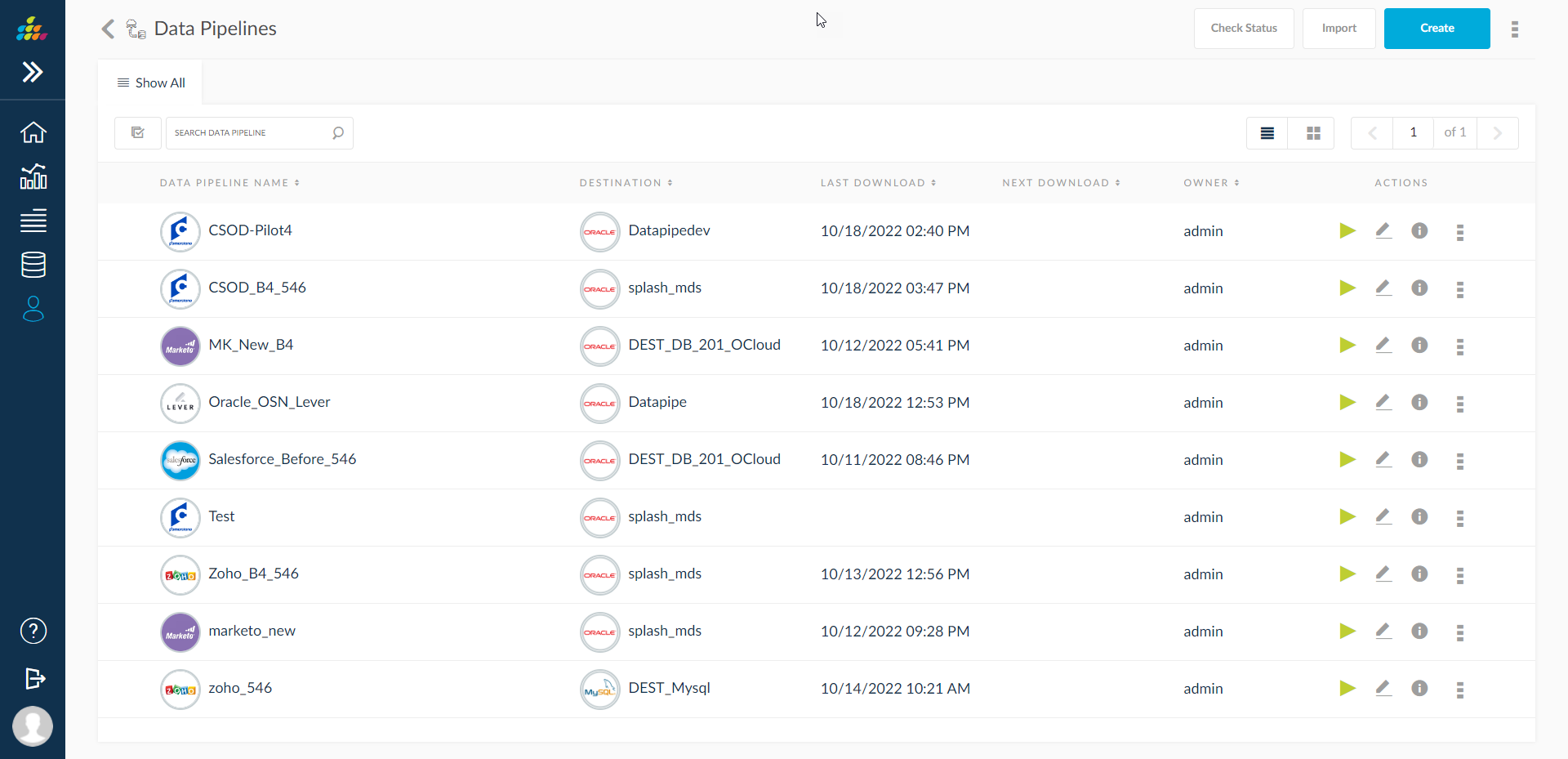
List of Data Pipelines
Data Pipelines list screen is presented to the user in grid view and list view as shown below.
List View
Grid View

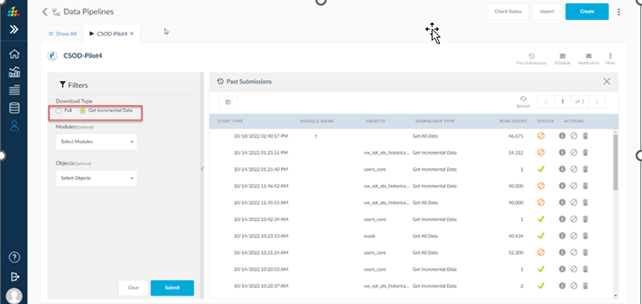
Data Pipelines Info
User can view the Data Pipelines full information by clicking on the info icon in the list page as shown in the below.
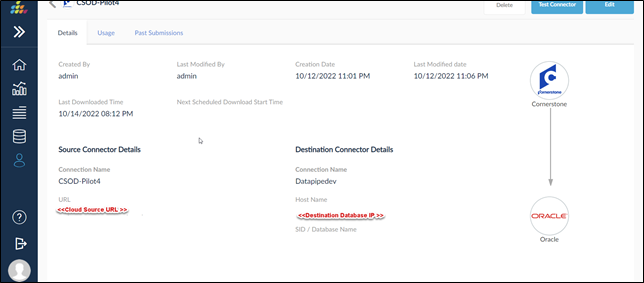
Details
This section shows the basic information of the data pipeline.
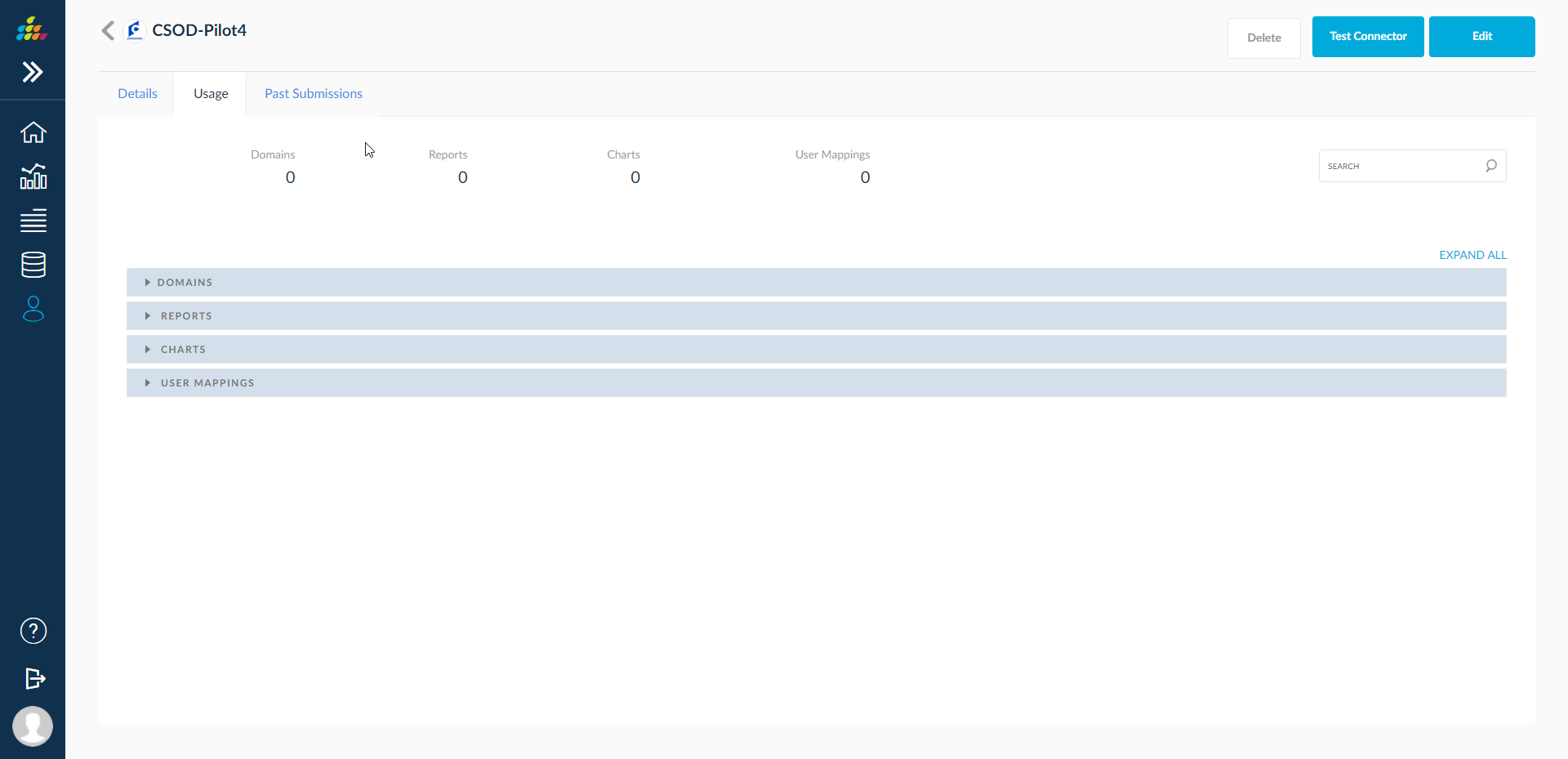
Usage
This section displays the domains, reports, charts, user mappings that might have built using the data pipeline loaded destination data source.
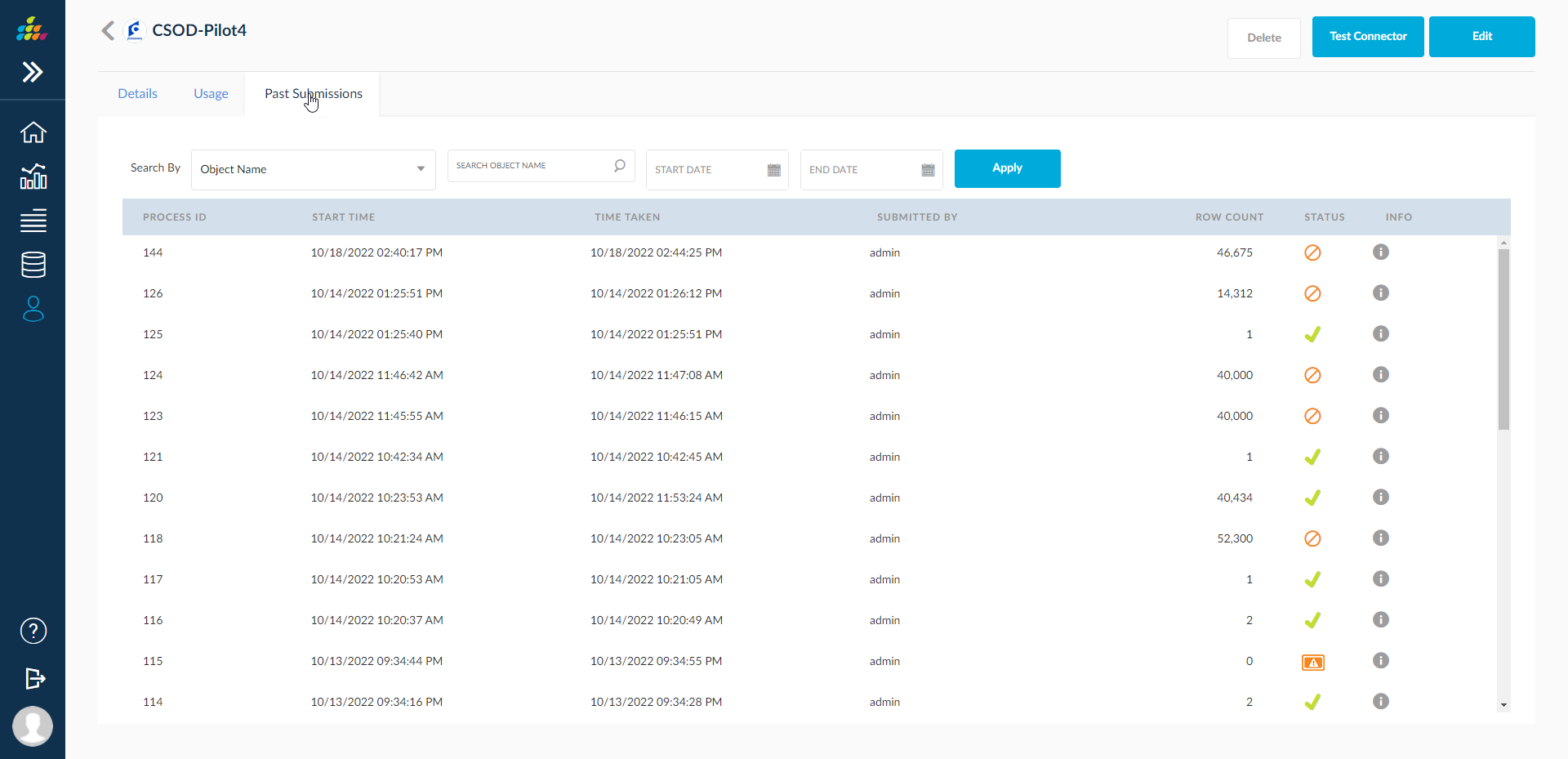
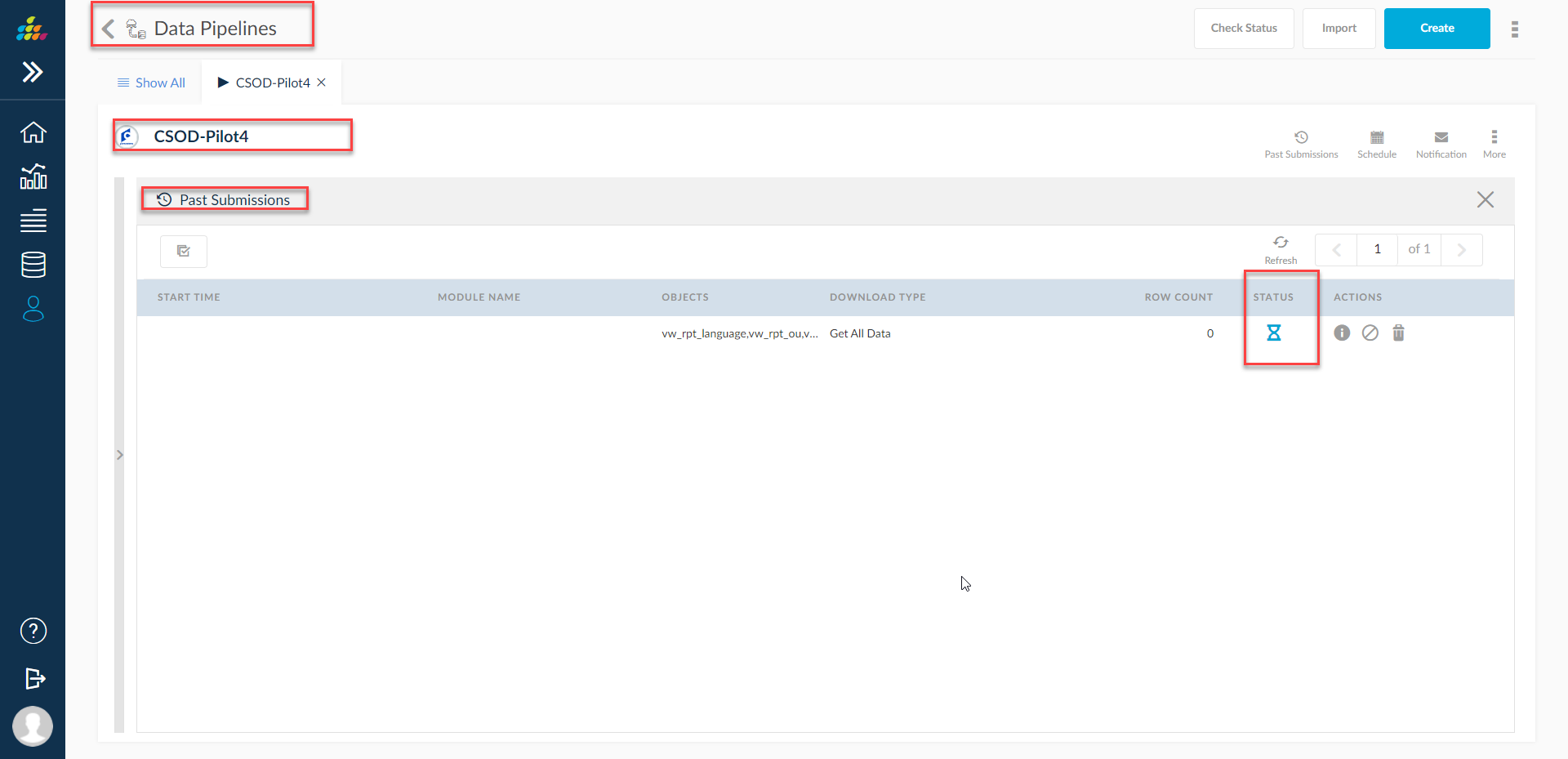
Past Submissions
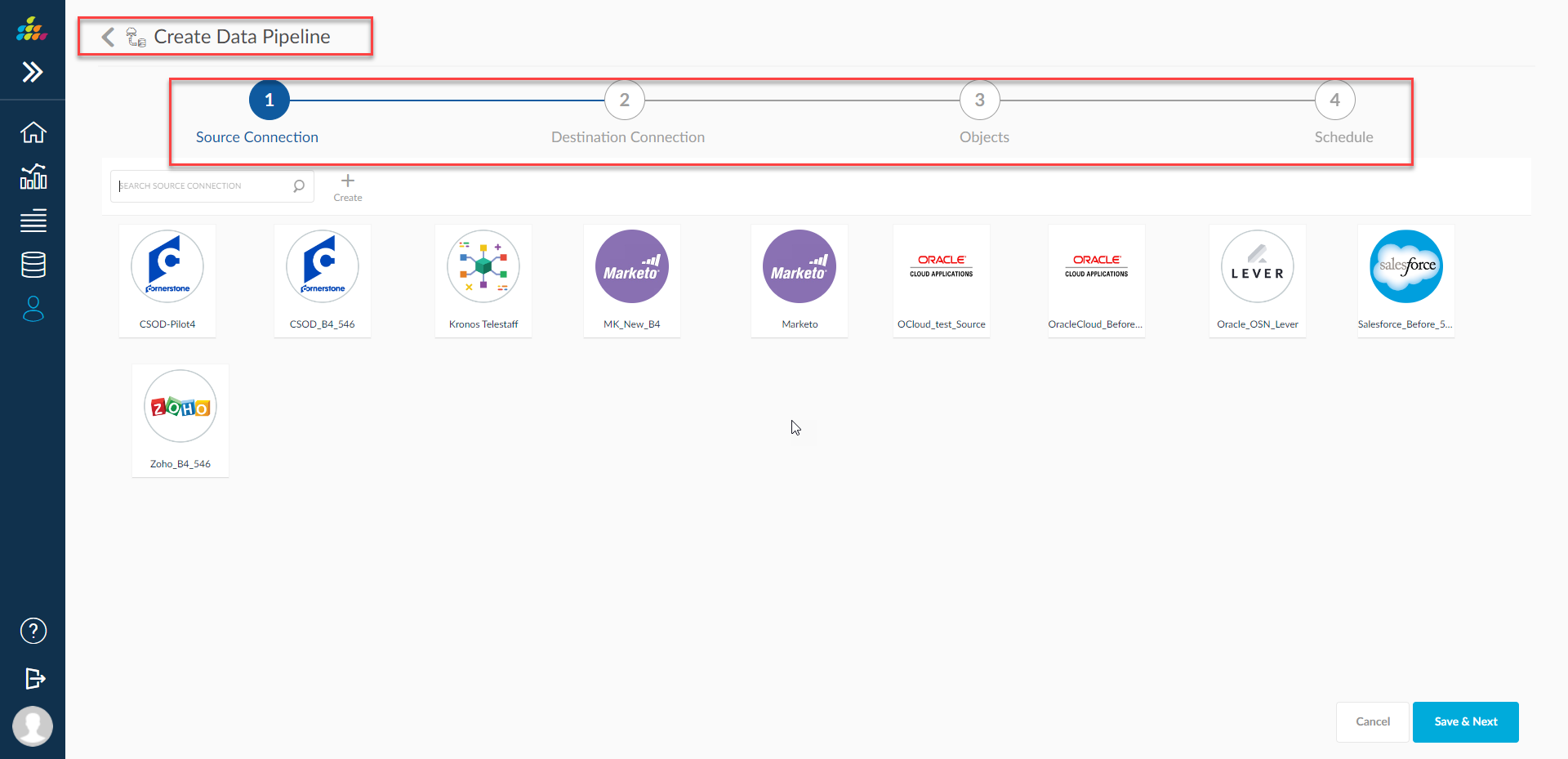
Create Data Pipeline
Creating Data Pipeline comprises below stages.
- Select Source Connection
- Select Destination Connection
- Select Objects to be Replicated
- Schedule Now or Later
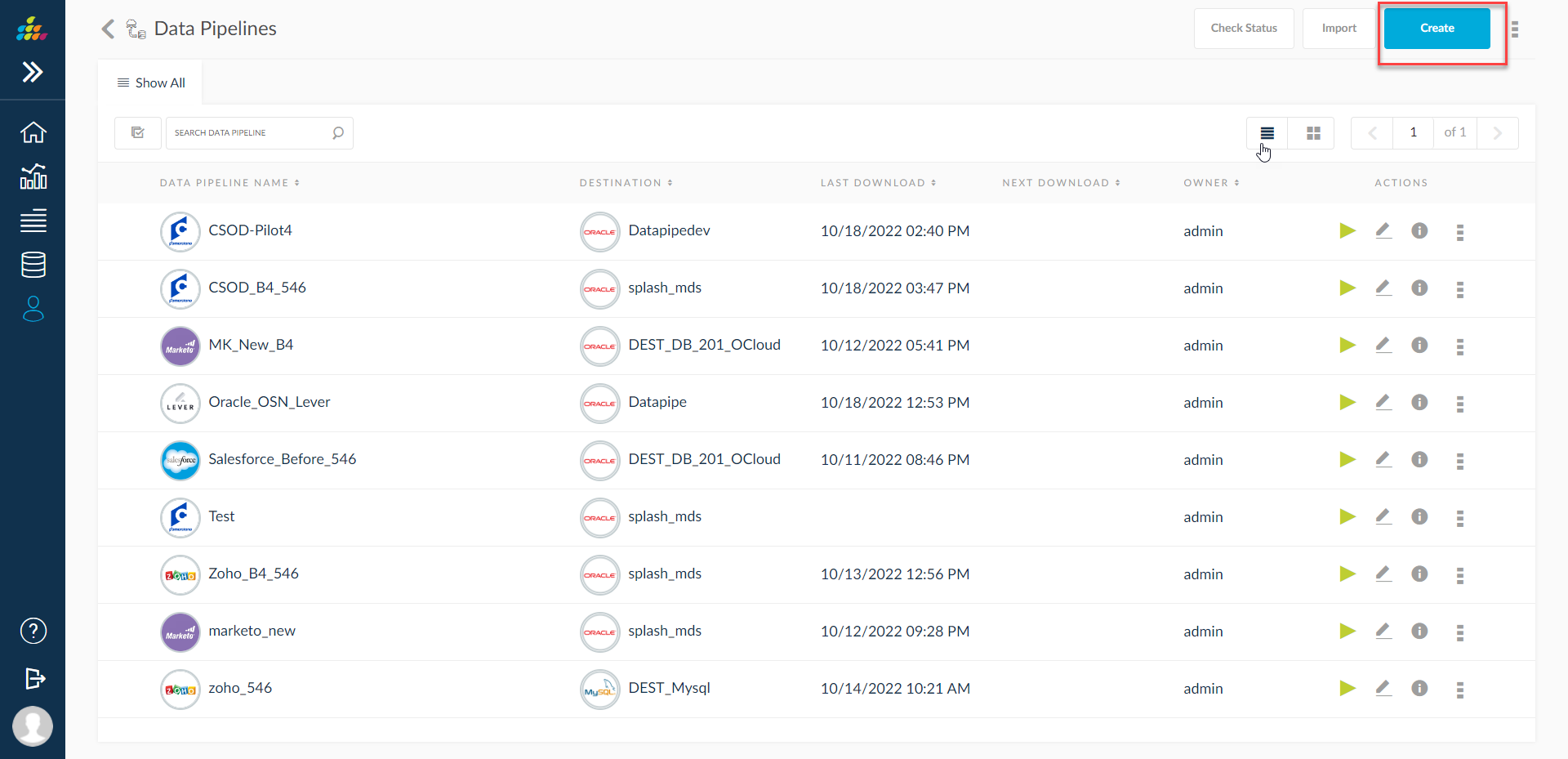
Clicking on Create button as shown in above screen shot, user is navigated to Create Data Pipeline screen as shown in below screen shot.
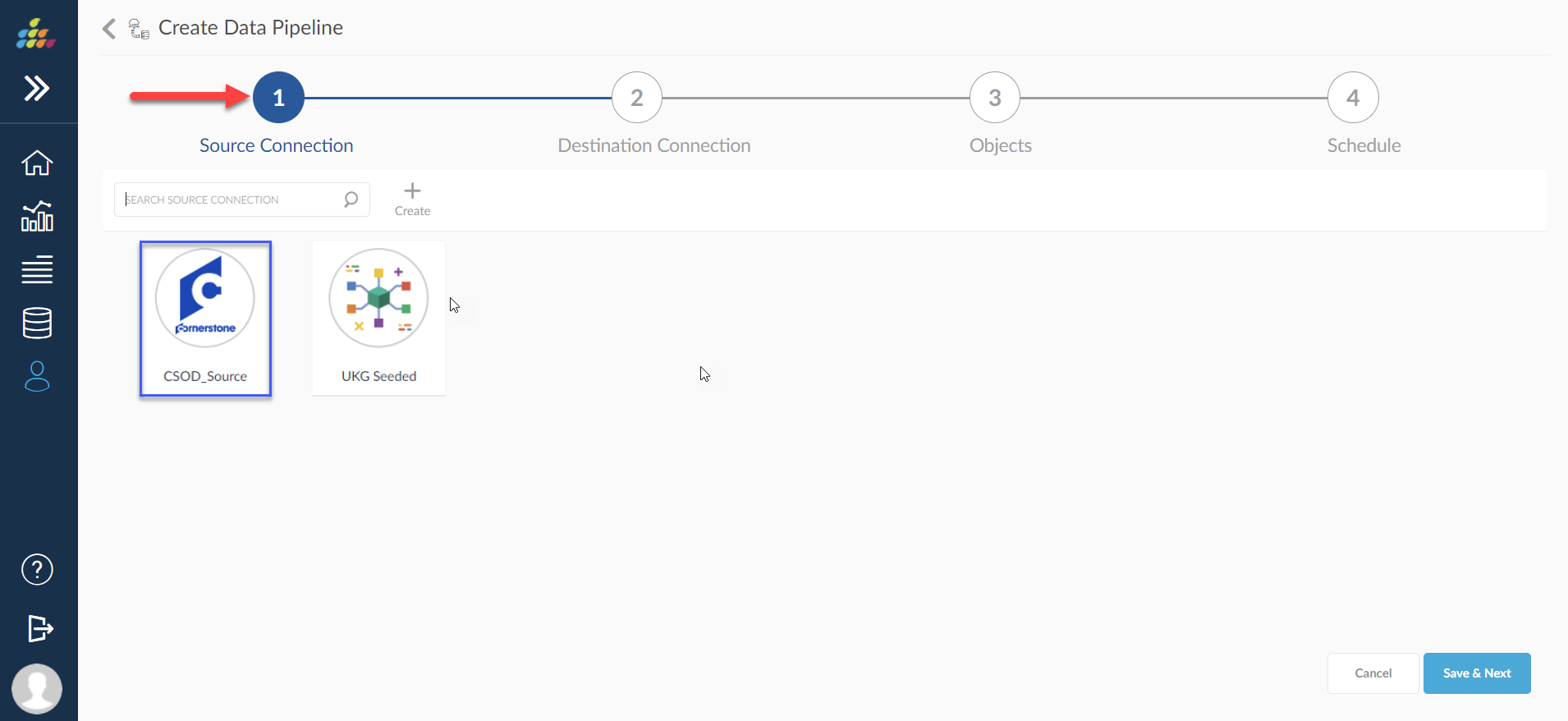
Source Connection
Source for a Data Pipeline is Cloud from which the data needs to be replicated to a database which should be created in Admin -> Connectors section.
User needs to select a source connection from the available list of connections or user can create a new connection using Create button as shown in below screen shot.
Once source connection is selected, user needs to click on Save & Next button to navigate to next stage.
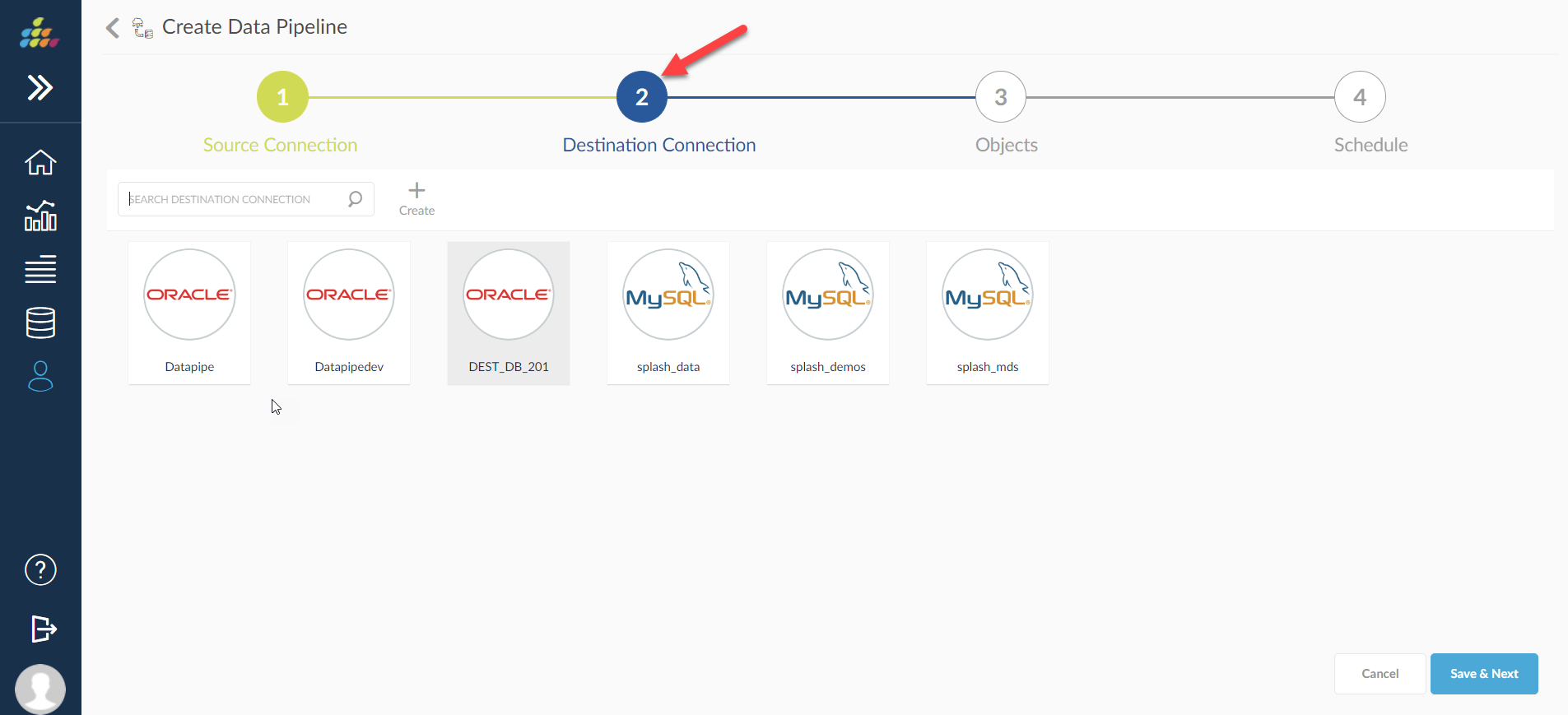
Destination Connection
Destination for a Data Pipeline is a database in which cloud data will be replicated as data warehouse.
User needs to select one of the available destination connections to replicate the data from source. Current supported destination databases are Oracle, PostgreSQL, SQL Server which will be increased in the future versions.
Objects
Select the objects from source to be replicated in the destination database. User can either can select all tables or required tables.
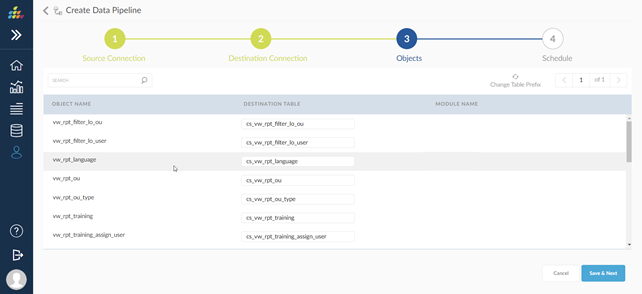
By default destination table name is populated with init case of the source table name.However, user can still change the prefix of the table names with Change Table Name Prefix option in the Objects screen.
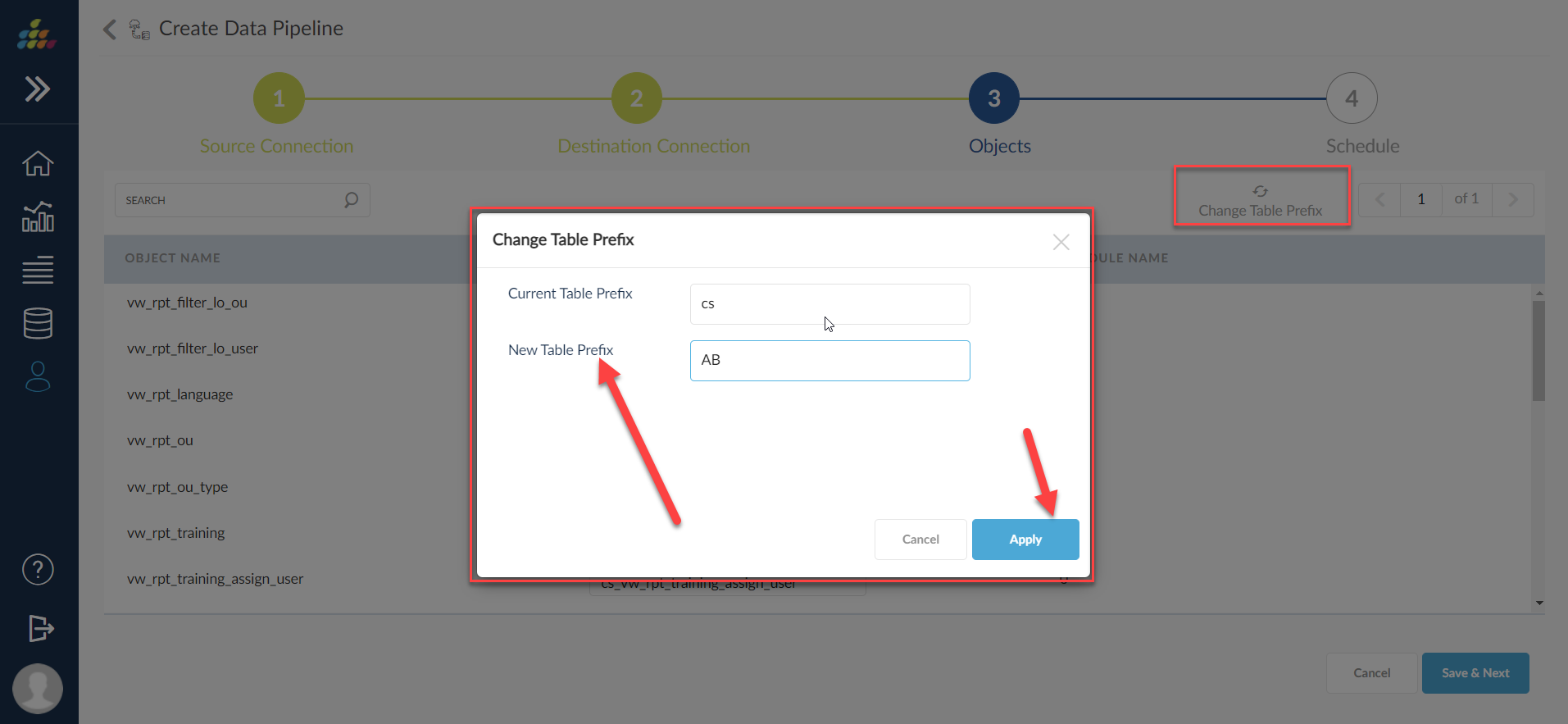
As user changes Current Table Prefix from CS to AB , all the destination table names prefix is changed to AB from CS
as shown in the below screen shot.
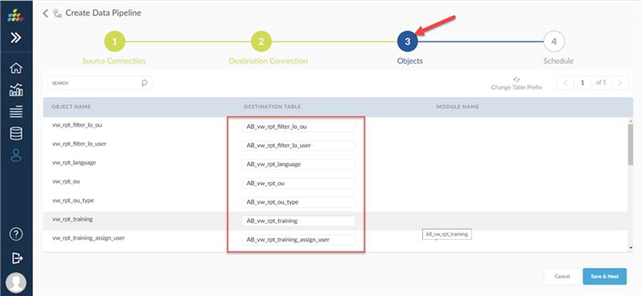
For example, as CSOD_Source is selected for the source connection which is based on the CSOD seeded connector, the objects screen would populate all the available seeded objects that are available.
Schedule Now or Later
Schedule screen provides 2 types of “Load Data” options for the user selection.
Now: Data Pipeline creation process will create all the objects and downloads the data as soon as Save Data Pipeline is clicked
Schedule Later: Data Pipeline process will trigger as per the scheduled time and then creates and loads the data at the triggered point of time.

Save Data Pipeline
Clicking on Save button in the last wizard option will prompt the user to enter Data Pipeline name as shown in the below screen shot.
Provide the Data Pipeline name and Description and click on save that saves the Data Pipeline that gets reflected in the Data Pipelines screen.

However, as in the background a process is fired to initiate the download process, the screen is navigated to the Past Submissions screen directly to view that a process is fired and can wait to see the completion of the process as well by clicking on refresh icon on the past submissions screen.
Edit Data Pipeline
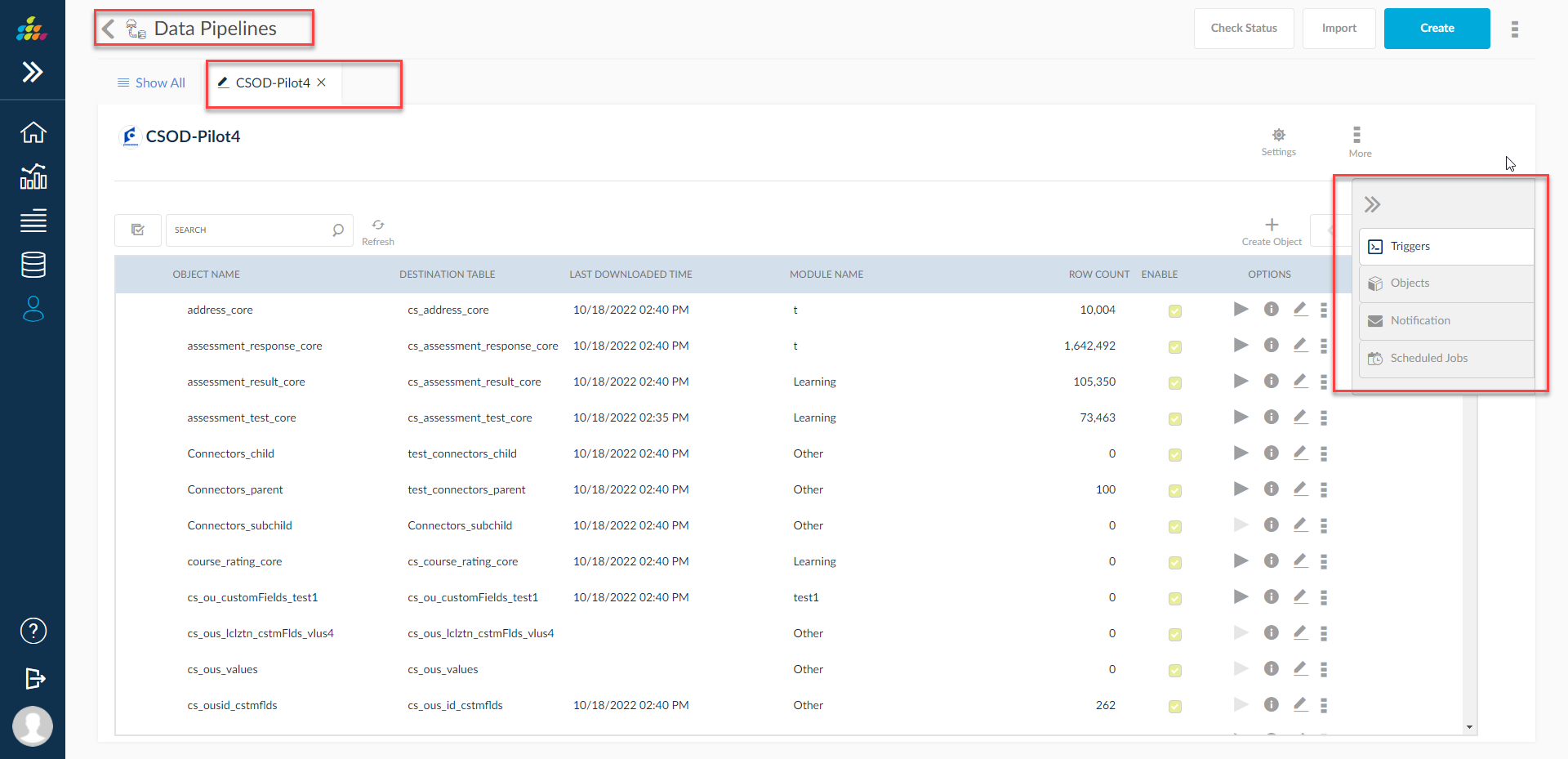
Clicking on edit icon of the data pipeline, user can do modifications to the pipeline as shown below.

Run Data Pipeline
User can run the data pipeline and schedule the data pipelines so that downloading of the data continue with the replicated tables.